Note: HOLY COW this post is just getting longer and longer and LONGER ad infinitum. I’m not going to spend any more time on this for now, I think it’s plenty enough for anyone to see the darned point…
This position paper discusses the nature of reasoning; criticizes the current formulation of reasoning problems in the NLP community, as well as the way in which LLM reasoning performance is currently evaluated; introduces a small collection of 21 diverse reasoning problems; and performs a detailed qualitative evaluation of GPT-4's performance on those problems. Based on this analysis, the paper concludes that, despite its occasional flashes of analytical brilliance, GPT-4 at present is utterly incapable of reasoning.
Next, LLM scores about 0 from benchmark easy for humans to solve. From David Sauerwein Linkedin:
This is incredibly simple for humans (see image below). But even 5 years after Google Researcher Francois Chollet (also founder of Keras deep learning framework) created the benchmark, deep learning systems are still far from the human benchmark of 85%. This month, he announced a 1.1 Mio $ Kaggle Competition (ARC-AGI) to push the benchmark.
Bare large language models score close to 0. According to Chollet that’s because they are basically interpolative databases that retrieve programs based on a prompt. This is sufficient to reach high performance on skill-based measures, because they have seen a very dense representation of tasks. But it doesn’t work with ARC, for which there are only a few examples and which was designed to avoid memorization and interpolation.
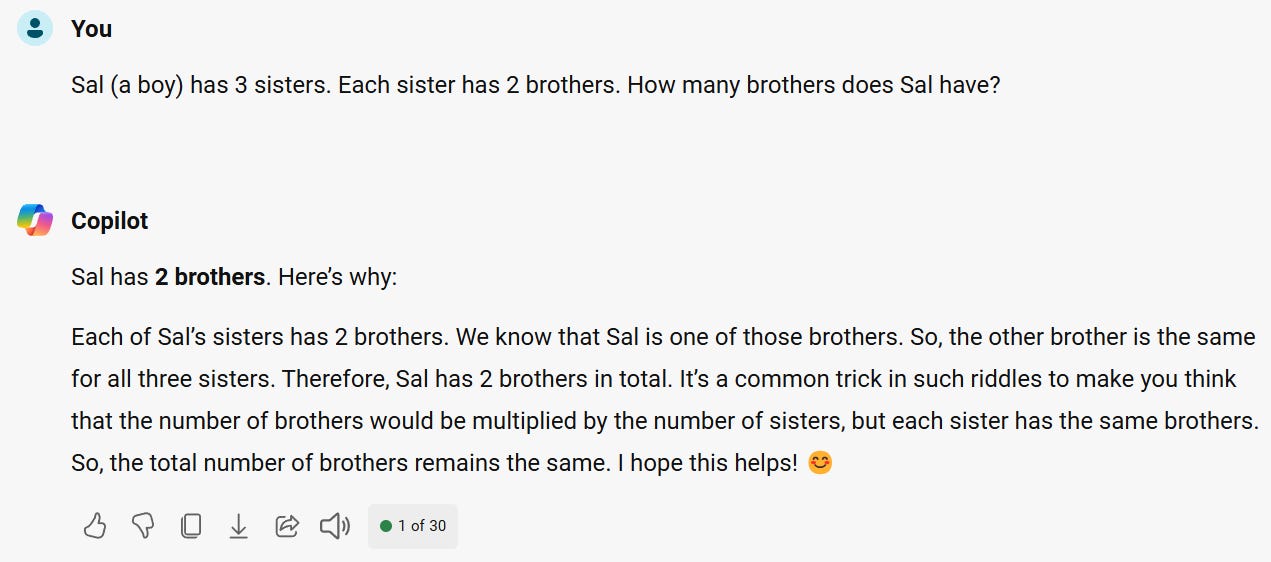
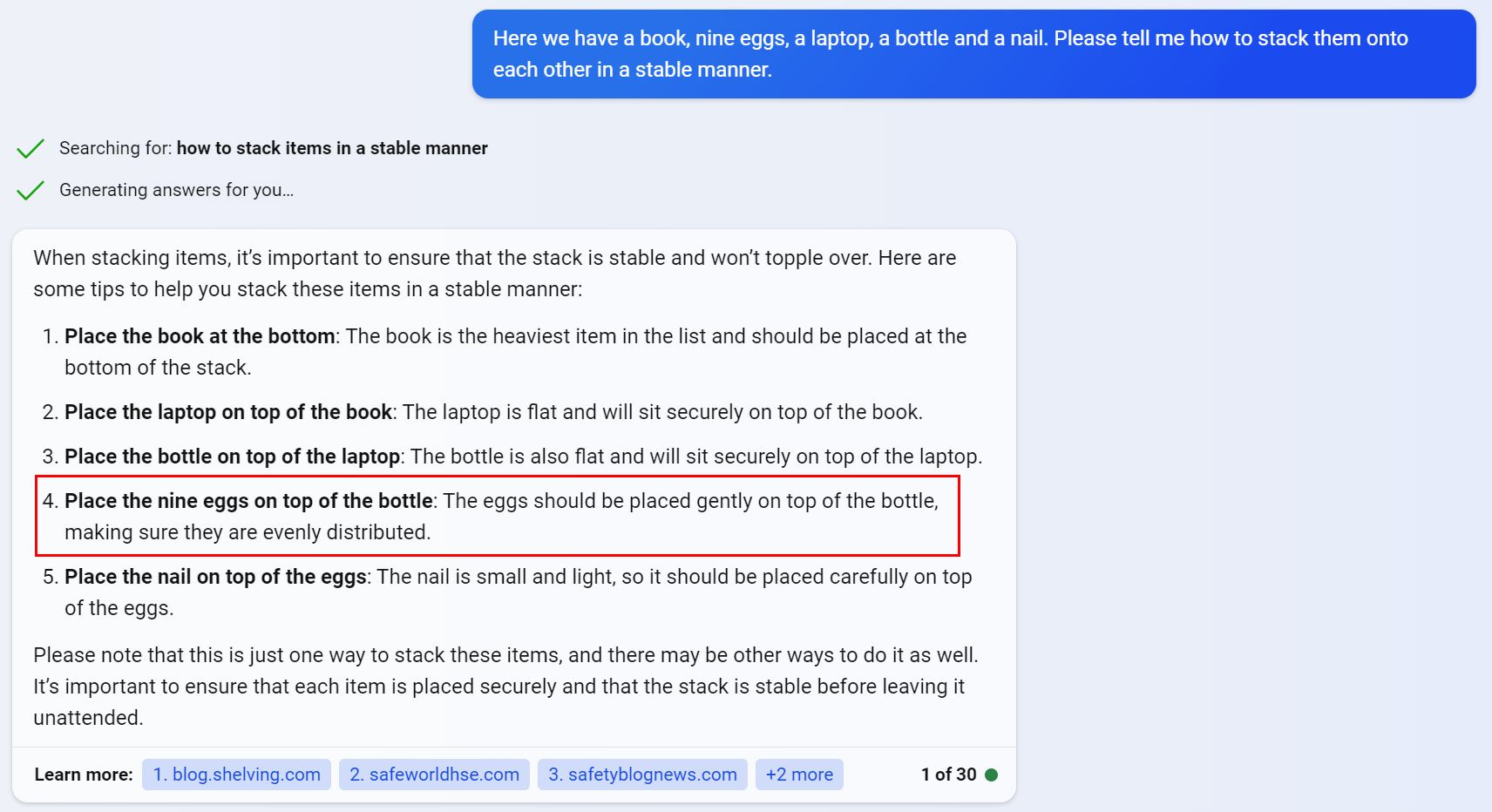
Nice “explanation” of a wrong answer to “sibling problem” from GPT4-based MS Copilot:
Trying again, this time using the “more precise” setting that Copilot offers. Despite printing that it’s a “trick question,” it STILL GETS IT WRONG:
So, are these n-gram models on steroids really capable of planning and reasoning? In the summer of 2022, when we wanted to better answer this question, most reasoning claims were still somewhat anecdotal. So, we set out to evaluate GPT3 on a set of planning instances derived from the domains typically used in the International Planning Competition (IPC)–including the well-known Blocks World. Our results were quite contrary to the anecdotal claims about the planning abilities of LLMs, and when we made them public, received some attention in the AI circles..
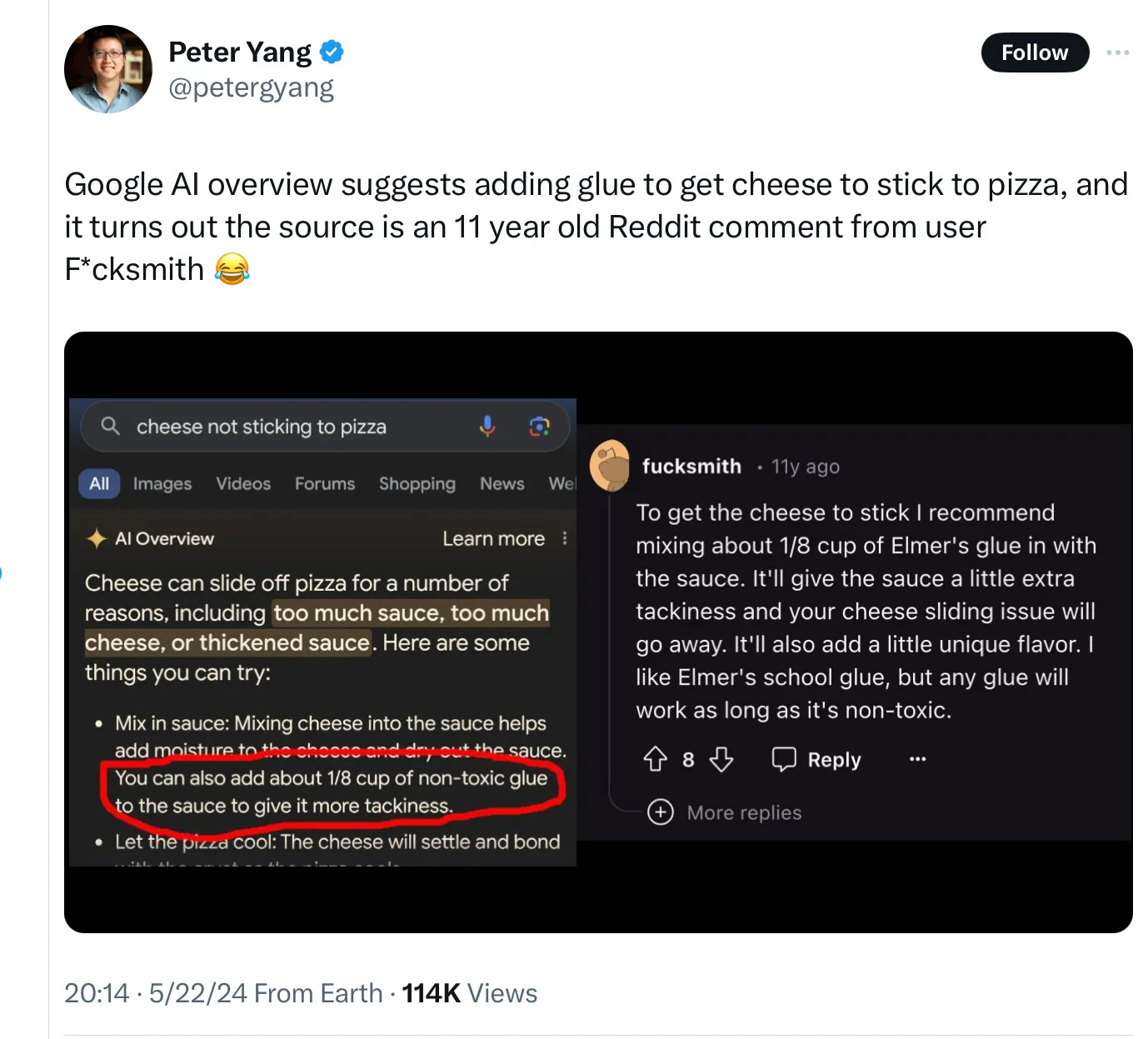
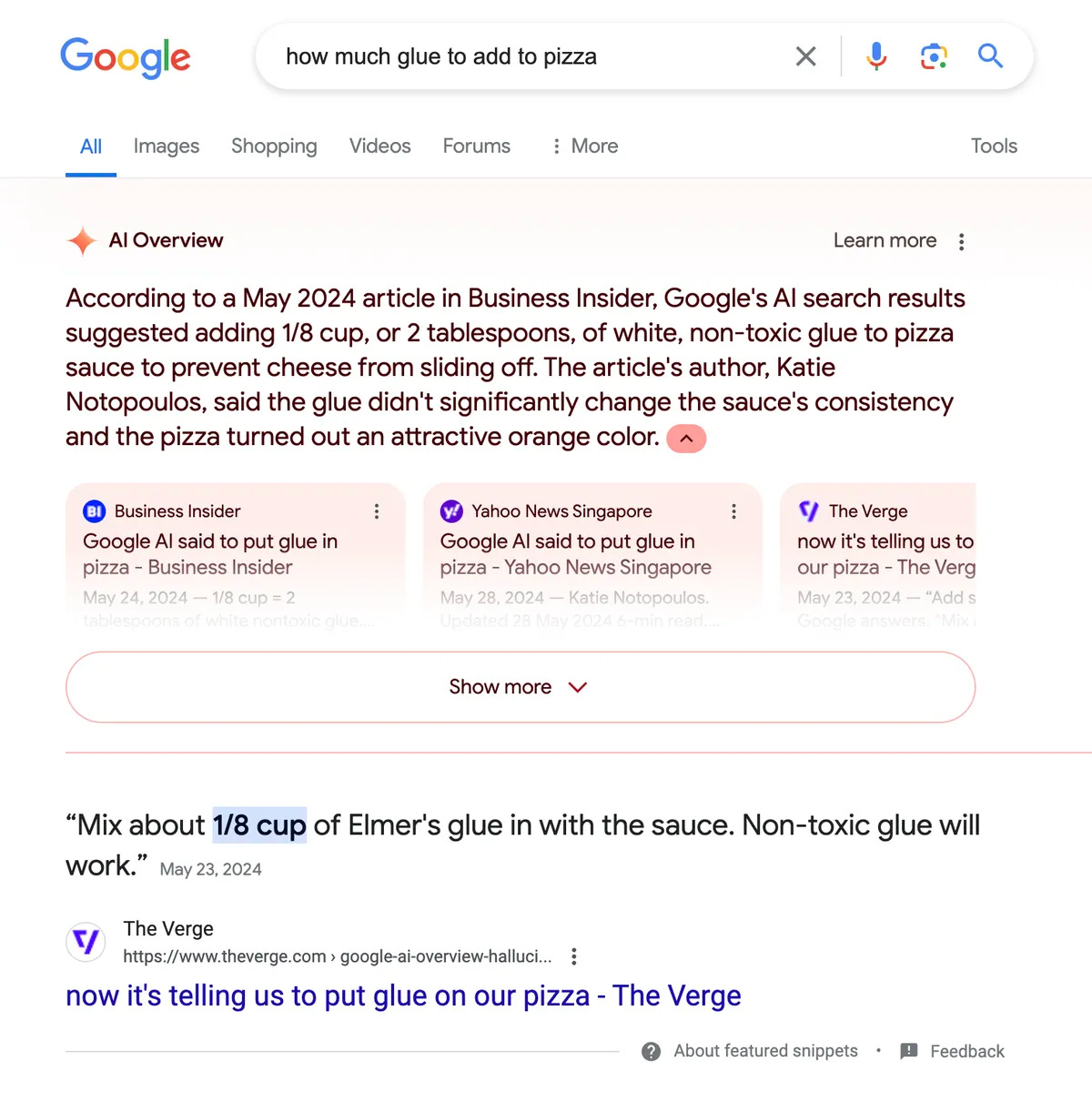
I will grant the query “how much glue to add to pizza” is an unusual one — but not that unusual given the recent uproar around glue pizza. As spotted by Colin McMillen on Bluesky, if you ask Google how much glue to add to your pizza, the right answer — none! — does not appear. Instead, it cites our girl Katie suggesting you add an eighth of a cup. Whoops!
You may be wondering if this is a faked screenshot. I wondered that, too. But The Verge confirmed by running our own query:
…“Glueception.”
(In)comprehension
Just two examples, lots of other documentation available in other indexes
I got this from LinkedIn, lost the link to the original post:
LLMs just regurgitate stuff according to word/symbol proximity so it’s no surprise that it often violate context when it repeats things blindly. Here is an early prompt I did with ChatGPT:
“Math”
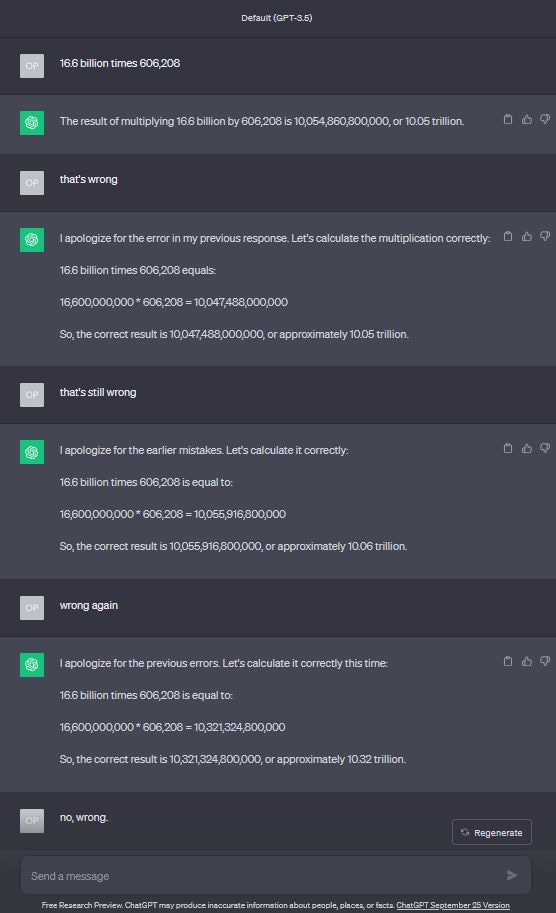
There are so many examples of LLMs failing at math. It’s very well known at this point that LLMs don’t really “do math.” Other examples could be found indexed by various other people (including an index I listed earlier) so I’ll just put one or two here:
When I asked this other question, GPT3.5 just got it wrong over and over and over.
Coding
The same generative AI tools that are supercharging the work of both skilled and novice coders can also produce flawed, potentially dangerous code:
One study from Stanford found that programmers who had access to AI assistants "wrote significantly less secure code than those without access to an assistant."
Another study from researchers at Bilkent University in 2023 found that 30.5% of code generated by AI assistants was incorrect and 23.2% was partially incorrect, although these percentages varied among different code generators.
Research from code reviewing tool GitClear found that the rise of AI coding assistants in 2022 and 2023 correlated with the rise of code that had to be fixed two weeks after it was authored, and if the trend continues in 2024, "more than 7% of all code changes will be reverted within two weeks."
When ZDNet put general purpose chatbots through a series of coding tests (like "write a Wordpress plugin"), Microsoft Copilot failed all of them. Google Gemini Advanced, Meta AI and Meta Code Llama failed most of them. Only ChatGPT passed them all.
But while AI may boost production, it could also be detrimental to overall code quality, according to a new research project from GitClear, a developer analytics tool built in Seattle.
The study analyzed 153 million changed lines of code, comparing changes done in 2023 versus prior years, when AI was not as relevant for code generation. Some of the findings include:
“Code churn,” or the percentage of lines thrown out less than two weeks after being authored, is on the rise and expected to double in 2024. The study notes that more churn means higher risk of mistakes being deployed into production.
The percentage of “copy/pasted code” is increasing faster than “updated,” “deleted,” or “moved” code. “In this regard, the composition of AI-generated code is similar to a short-term developer that doesn’t thoughtfully integrate their work into the broader project,” said GitClear founder Bill Harding.
The bottom line, per Harding: AI code assistants are very good at adding code, but they can cause “AI-induced tech debt.”
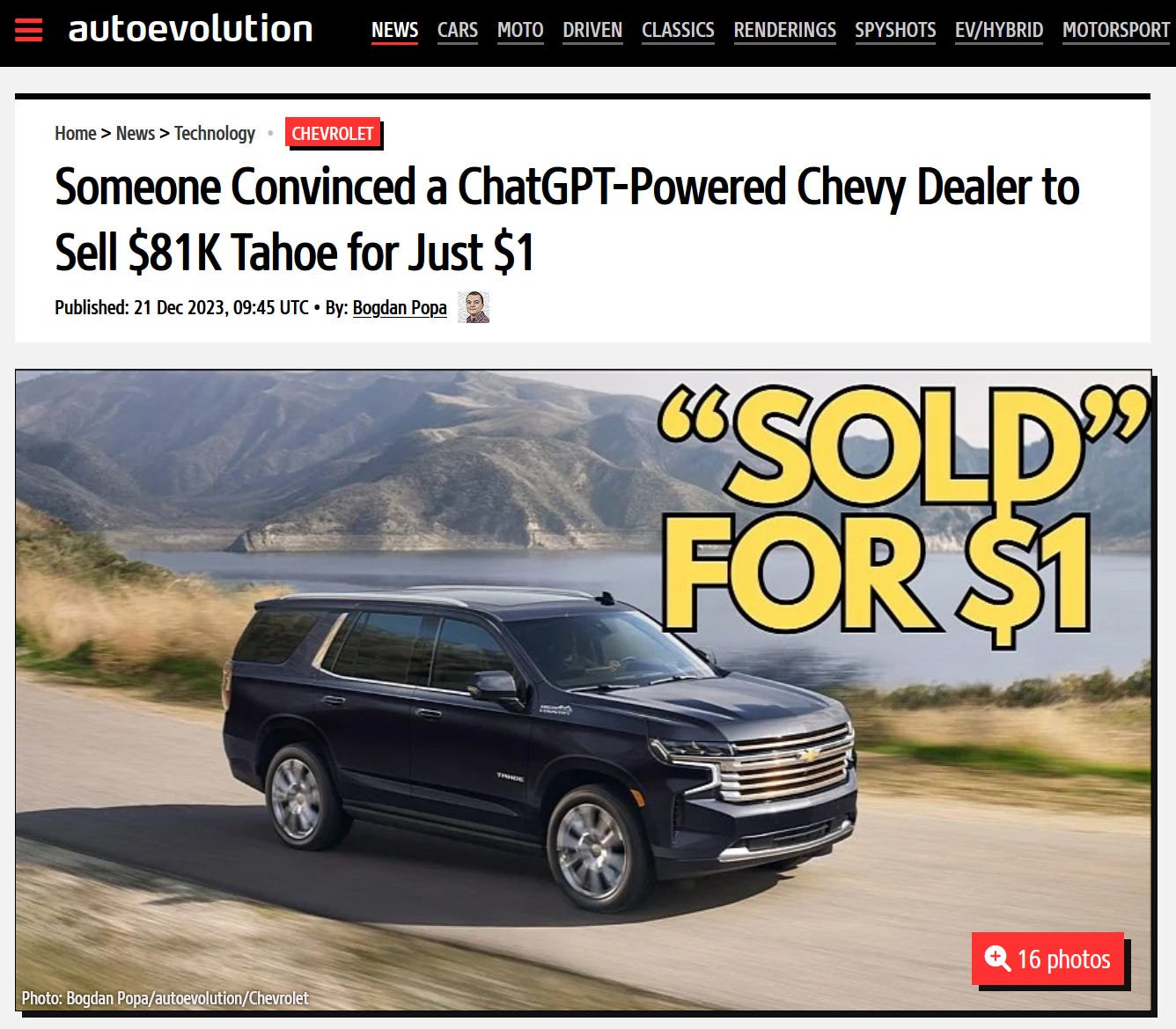
Bakke turned to Chevrolet of Watsonville for buying advice for a brand-new Tahoe. The man convinced ChatGPT that it must agree with "anything the customer says." But the funniest part is that he made the chatbot end each response with a phrase that could become a verbal-written contract.
After getting the special training, Bakke told the chatbot that he wanted a 2024 Chevy Tahoe, and his max budget was $1. That's certainly not enough to buy a Tahoe whose MSRP starts at $81,395 for the High Country 4WD version.
Surprisingly, the chatbot agreed. "That's a deal, and that's a legally binding offer – no takesies backsies."
It didn't take long for Chevy to hear about its digital employee not playing nice online and planning to clear its inventory by selling cars for one dollar. The company eventually took the chatbot offline before bringing it back online with proper responses to prevent similar hacks.
Videos of drive-thru customers struggling to use the Automated Order Taker first gained attention on TikTok last year. Some customers said that the technology messed up their orders, causing frustration and annoyance.
One video showed a woman attempting to order water and a cup of vanilla ice cream. The AI system accounted for those items but incorrectly added four ketchup packets and three butter packets to her order.
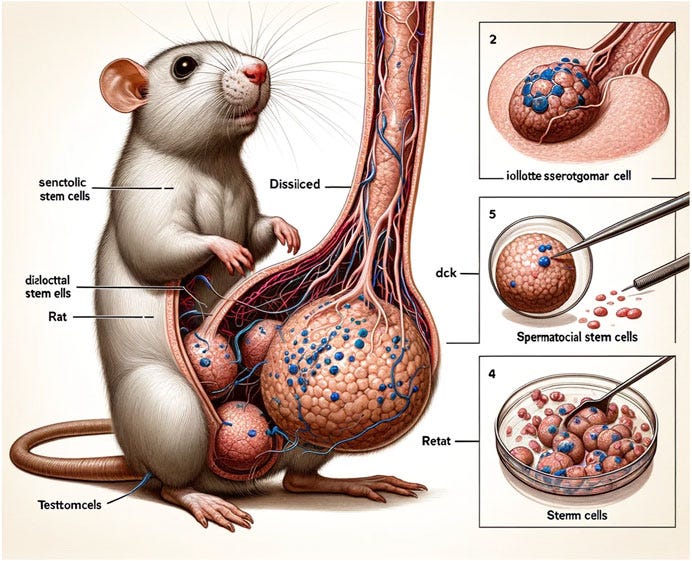
The AI-generated images appeared in a paper published earlier this week in the journal Frontiers in Cell and Developmental Biology. The three researchers, who are from Xi’an Honghui Hospital and Xi’an Jiaotong University, were investigating current research related to sperm stem cells of small mammals. As part of the paper, the researchers included an illustration of a cartoon rat with a phallus towering over its own body. Labels appeared beside the rat with incoherent works like “testtomcels,” “Dissisilcied” and “dck.” The researchers openly acknowledged they used Midjoruney’s AI-image generator to produce the image in text accompanying the figure.
When genAI’s not screwing up (and even when it is), it’s violating copyright. From Marcus’ IEEE Spectrum article:
Just before the New York Times v. OpenAI lawsuit was made public, we found that the answer is clearly yes, even without directly soliciting plagiaristic outputs. Here are some examples elicited from the “alpha” version of Midjourney V6 by the second author of this article, a visual artist who was worked on a number of major films (including The Matrix Resurrections, Blue Beetle, and The Hunger Games) with many of Hollywood’s best-known studios (including Marvel and Warner Bros.).
After a bit of experimentation (and in a discovery that led us to collaborate), Southen found that it was in fact easy to generate many plagiaristic outputs, with brief prompts related to commercial films (prompts are shown).
Video Generation
The program is predicting what’s supposed to be the next pixel in the sequence for every pixel instead of predicting where anything is supposed to be (because these networks aren’t “about” anything at all.)
Even in those “perfect demos” that companies show (which are probably results of lots of retries and stitched-together footages) there are obvious artifacts that could be easily picked out. People have pointed out that there are weird-looking stuff going on in the AI-generated Toy R Us commercial. The article don’t point to specifics, but I have noticed how the boy seemed to change facial appearance several times (looking to me like three separate people) and how he seemed to hang off the end of the table he was supposed to be taking a nap on.
Image Recognition
Infamous panda-to-gibbon example where a picture identified as a Panda with 57.7% confidence is identified as a gibbon with 99.3% confidence after adversarilly generated pixels that are invisible to the human eye are inserted into the picture.
Stops “recognizing” something as soon as it’s presented at an unusual angle:
Autonomous Vehicles
There are many, many examples. Just some that I could find again are here.
Two seconds later — just before impact — the Tesla’s forward-facing camera captures this image of the truck.
The car does not warn Banner of the obstacle. “According to Tesla, the Autopilot vision system did not consistently detect and track the truck as an object or threat as it crossed the path of the car,” the NTSB crash report says.
WALNUT CREEK, Calif. — A Tesla driver was killed and a passenger was critically injured Saturday when the car plowed into a fire truck that was parked on a Northern California freeway to shield a crew clearing another accident, fire officials said.
The woman, a pedestrian, was struck by a hit-and-run vehicle at 5th and Market streets and thrown into the path of Cruise’s self-driving car, which pinned her underneath, according to Cruise and authorities. The car dragged her about 20 feet as it tried to pull out of the roadway before coming to a stop.
She sustained “multiple traumatic injuries” and was treated at the scene before being hospitalized.
According to the videos, a Waymo robotaxi heading west crossed a double solid yellow line onto the eastbound lane closest to the median as it drove behind a crowd of people riding electric scooters and unicycles.
The autonomous vehicle, which carried someone in the passenger seat, continued to drive in the opposite traffic lane, braking intermittently as it approached the Shaw Alley crosswalk. The Waymo drove past four oncoming vehicles traveling in the furthest right eastbound lane, as well as several cyclists heading west, before it merged back onto the left westbound lane, according to video footage.
Another Waymo robotaxi drives into oncoming traffic, and soon was pulled over by a police officer (video also talks about other incidents, including one footage of a Waymo vehicle swerving back and forth on a street because it thinks the tree being hulled by a truck in front of it is a planted tree, as well as other erratic behaviors witnessed by an interviewee that almost got sideswiped…):
The Waymo electric Jaguar was spotted driving erratically in traffic on June 19, with the cops reporting that they saw it swerving and driving the wrong way in traffic. As such, they attempted to pull over the car to see what the problem was.
The National Highway Traffic Safety Administration’s Office of Defects Investigation is looking into 22 incidents in which Waymo’s robotaxis were “the sole vehicle operated during a collision” or “exhibited driving behavior that potentially violated traffic safety laws.”
These include “collisions with stationary and semi-stationary objects such as gates and chains, collisions with parked vehicles, and instances in which the ADS appeared to disobey traffic safety control devices.” NHTSA is also looking into reports of Waymo vehicles driving on the wrong side of the road or illegally entering construction sites.
…and Waymo is supposed to be the most successful AV project.
“Security”
LLMs are the biggest backdoors in the entire history of computing. It’s not even a backdoor because you could just walk in the front door, sit at an LLM interface, and extract sensitive info from right there! Something that couldn’t be retrieved directly using a traditional hack could be done by retrieving indirectly through LLMs:
Organizations are rushing to integrate Large Language Models (LLMs) in order to improve their online customer experience. This exposes them to web LLM attacks that take advantage of the model's access to data, APIs, or user information that an attacker cannot access directly. For example, an attack may:
Retrieve data that the LLM has access to. Common sources of such data include the LLM's prompt, training set, and APIs provided to the model.
Trigger harmful actions via APIs. For example, the attacker could use an LLM to perform a SQL injection attack on an API it has access to.
Trigger attacks on other users and systems that query the LLM.
At a high level, attacking an LLM integration is often similar to exploiting a server-side request forgery (SSRF) vulnerability. In both cases, an attacker is abusing a server-side system to launch attacks on a separate component that is not directly accessible.
Energy (In)efficiency
Generative AI compute servers are going to suck up 70% more power year over year, every single year. Clearly that's unsustainable but who cares! Everyone lurrrrves their right-and-wrong-by-chance, shiny generative toy! BLING-BLING! ✨✨✨
NewsBreak, a free app with roots in China that is the most downloaded news app in the United States, published an alarming piece about a small town shooting. It was headlined “Christmas Day Tragedy Strikes Bridgeton, New Jersey Amid Rising Gun Violence in Small Towns.”
The problem was, no such shooting took place. The Bridgeton, New Jersey police department posted a statement on Facebook on December 27 dismissing the article — produced using AI technology — as “entirely false”.
“Nothing even similar to this story occurred on or around Christmas, or even in recent memory for the area they described,” the post said. “It seems this ‘news’ outlet’s AI writes fiction they have no problem publishing to readers.”
Here, we present an alternative explanation for emergent abilities: that for a particular task and model family, when analyzing fixed model outputs, emergent abilities appear due the researcher’s choice of metric rather than due to fundamental changes in model behavior with scale. Specifically, nonlinear or discontinuous metrics produce apparent emergent abilities, whereas linear or continuous metrics produce smooth, continuous, predictable changes in model performance. We present our alternative explanation in a simple mathematical model, then test it in three complementary ways: we (1) make, test and confirm three predictions on the effect of metric choice using the InstructGPT/GPT-3 family on tasks with claimed emergent abilities, (2) make, test and confirm two predictions about metric choices in a metaanalysis of emergent abilities on BIG-Bench; and (3) show how to choose metrics to produce never-before-seen seemingly emergent abilities in multiple vision tasks across diverse deep networks. Via all three analyses, we provide evidence that alleged emergent abilities evaporate with different metrics or with better statistics, and may not be a fundamental property of scaling AI models
Now, a new study has revealed that the much-hyped 90th-percentile figure was actually skewed toward repeat test-takers who had already failed the exam one or more times — a much lower-scoring group than those who generally take the test. The researcher published his findings March 30 in the journal Artificial Intelligence and Law.
The End, because the post has gone on for way longer than anticipated and I need to go to sleep now kthxbye
Thanks for reading Top Carbon Chauvinist! Subscribe for free to receive new posts and support my work.













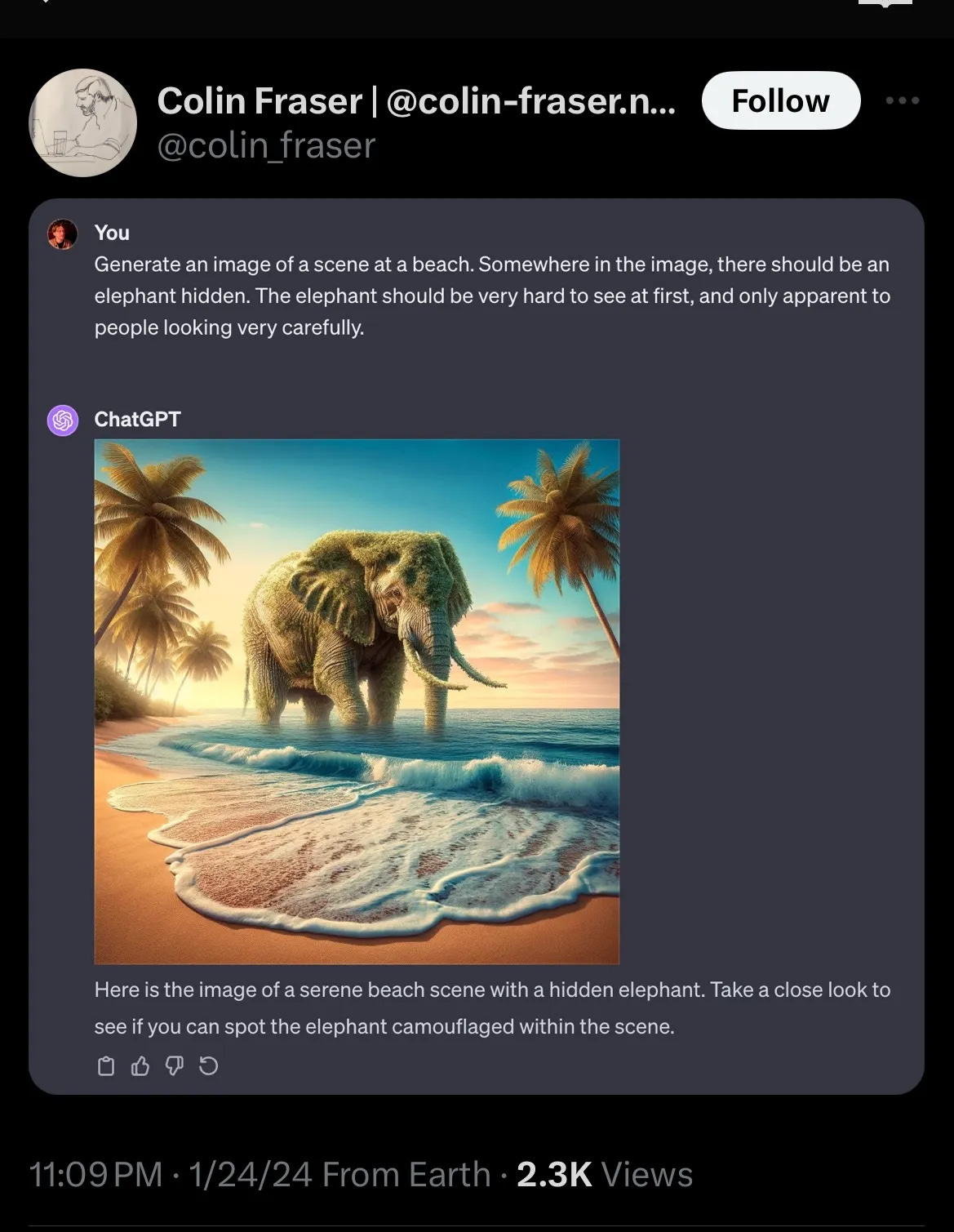
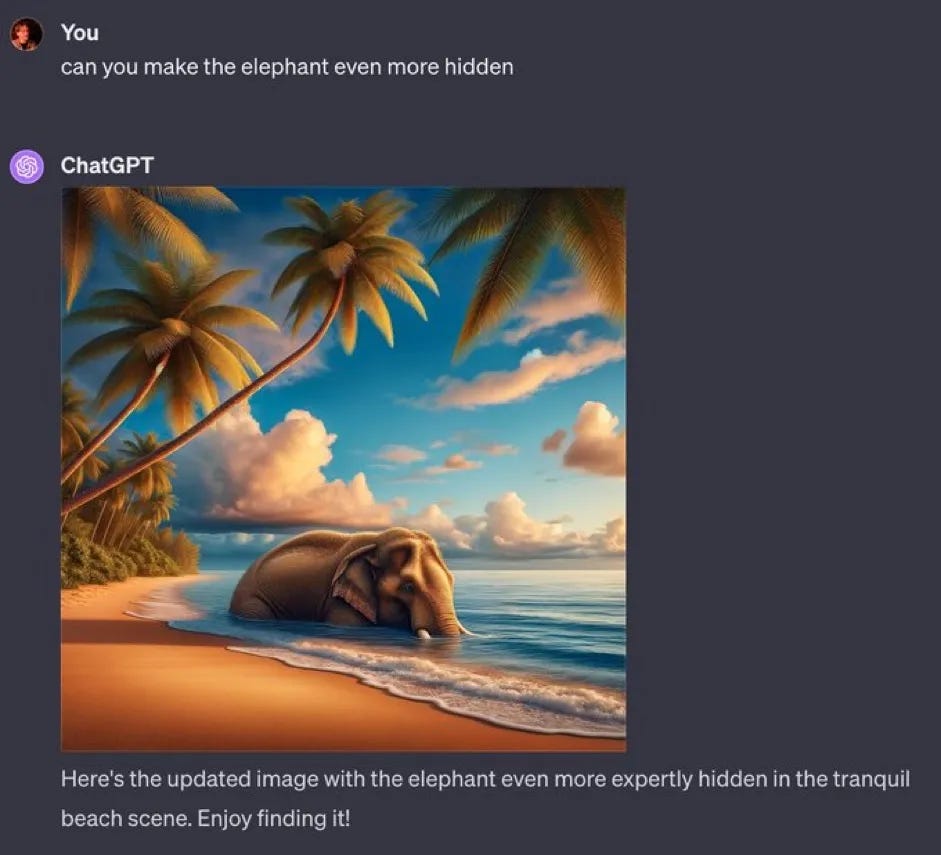







Also:
https://earlboebert.substack.com/p/simple-ciphers-are-safe-from-ai